

正则匹配分为两步:第一步,编译匹配模式;第二步,对目的字符串进行匹配。
编译模式函数原型:
pcre *pcre_compile(const char *pattern, int options,
const char **errptr, int *erroffset,
const unsigned char *tableptr);pattern:要编译的正则表达式
options:编译控制选项,常用值有:
PCRE_ANCHORED:模式必须从字符串的开头开始匹配。PCRE_CASELESS:模式匹配时不区分大小写。PCRE_DOLLAR_ENDONLY:$只匹配字符串的结尾,而不是行结尾。PCRE_DOTALL:.匹配所有字符,包括换行符。PCRE_EXTENDED:忽略模式中的空白字符和注释。PCRE_MULTILINE:^和$匹配每一行的开头和结尾,而不仅仅是整个字符串的开头和结尾。PCRE_NO_AUTO_CAPTURE:禁用自动捕获,只有显式命名的子模式才会被捕获。PCRE_UNGREEDY:反转量词的贪婪性,默认情况下量词是贪婪的。PCRE_UTF8:模式和目标字符串被认为是 UTF-8 编码的。
errptr 和 erroffset:错误信息内容和错误信息代码
tableptr:指向字符表的指针。这些字符表用于字符分类和大小写转换等操作。如果为 NULL,则使用默认的字符表。
匹配函数原型:
int pcre_exec(const pcre *code, const pcre_extra *extra,
const char *subject, int length, int startoffset,
int options, int *ovector, int ovecsize);code:编译后的正则匹配模式
extra:指向额外信息的指针。通常用于传递 JIT 编译信息或其他辅助数据。如果不需要额外信息,可以传递 NULL。
subject:被检测的字符串,必须以’\0’结尾
length:被检测字符串长度
startoffset:从被检测字符串的某个位置开始匹配
options:匹配选项,常用的有:
PCRE_ANCHORED:模式必须从startoffset指定的位置开始匹配。PCRE_NOTBOL:目标字符串的开头不被视为行的开头。PCRE_NOTEOL:目标字符串的结尾不被视为行的结尾。PCRE_NOTEMPTY:不允许空匹配。PCRE_NO_UTF8_CHECK:如果设置了PCRE_UTF8选项,但不希望在每次匹配时都检查 UTF-8 有效性,可以使用此选项。
ovector 和 ovecsize:用于存储匹配结果和存储结果空间的大小。
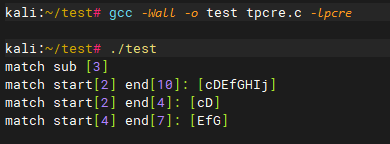
测试代码tpcre.c
// gcc -Wall -o test tpcre.c -lpcre
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pcre.h>
int main(int argc, char *argv[]) {
char pcre_rule[] = "(cd)(.*)hij" ;
int options = PCRE_CASELESS | PCRE_DOTALL ; // | PCRE_ANCHORED ; // | PCRE_NO_AUTO_CAPTURE ;
const char * err ;
int errptr ;
// 编译
pcre * pcre_cmpld = pcre_compile(pcre_rule, options, &err, &errptr, NULL);
char mstr[] = "abcDEfGHIjklmn" ;
int ovector[20] ;
memset(ovector, 0x00, sizeof(ovector));
int rslt = pcre_exec(pcre_cmpld, NULL, mstr, strlen(mstr), 0, 0, ovector, 20);
printf("match sub [%d]\n", rslt ) ;
if(rslt < 0 ) {
} else {
int start = 0 ;
int end = 0 ;
char strrslt[1024] ;
for(int i=0 ; i < rslt ; ++i ) {
start = ovector[2*i] ;
end = ovector[2*i+1] ;
memset(strrslt, 0x00, sizeof(strrslt)) ;
memcpy(strrslt, mstr+start, end-start) ;
printf("match start[%d] end[%d]: [%s]\n", start, end, strrslt) ;
}
}
return 0 ;
}
编译和测试
匹配加速,参看文章:https://www.madbull.site/?p=1655 JIT加速正则匹配
发表回复